
ディープラーニングとは…人間の脳をまねた人工知能技術
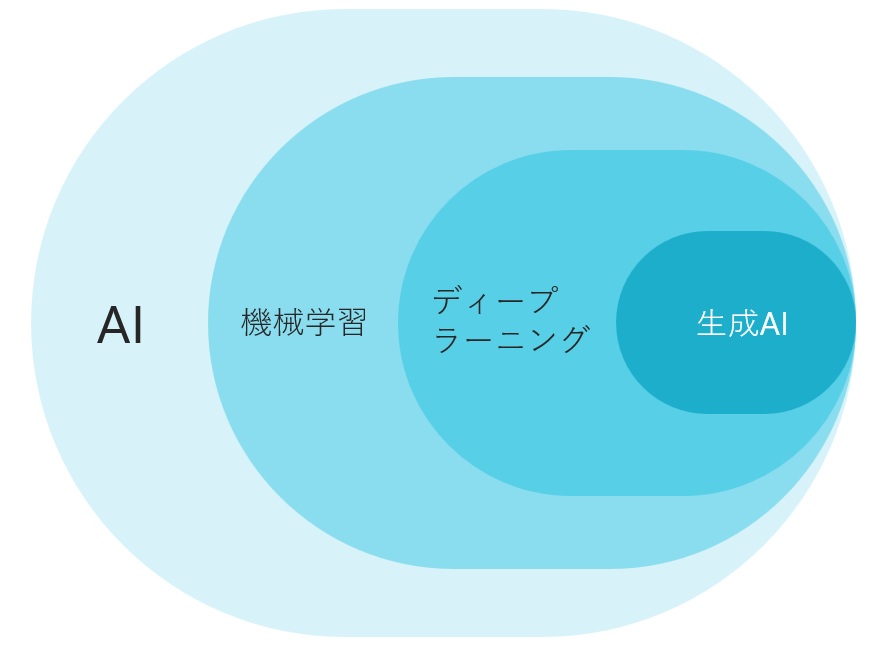
ディープラーニングは、機械学習の一分野です。特に多層のニューラルネットワークを用いてデータから特徴を自動的に学習します。
この技術は、人間の脳の神経回路を模倣した構造を持ち、入力データを処理するための複数の層を持っています。
これにより、複雑なパターンやルールを学習し、画像認識や音声認識、自然言語処理などのタスクを高精度で実行することが可能になります。
ディープラーニングをわかりやすく解説!
ディープラーニングは一言で表すと、「人間の脳の仕組みを真似て学ぶAIの技術」です。
たくさんのデータを使って、「これって何?」ということを自分で理解できるようになる仕組みです。
ディープラーニングの動き方・出力プロセス
入力層、隠れ層、出力層の3層構造で、各層のニューロンが互いにつながっています。
データは各層を通過する際に、重要度(重み)と判断基準(活性化関数)によって処理され、最終的な結論が導き出されます。
私たちが「りんご」を見分ける時、以下のプロセスをたどります。
| 1.入力層(目) | りんごの色や形を見る。 |
| 2.隠れ層(脳) | 「赤くて丸い」「つやがある」といった特徴を処理。 |
| 3.出力層(脳) | 「これはりんごだ!」と判断し結論を出す。 |
ディープラーニングも同じようなプロセスで結論を導きます。
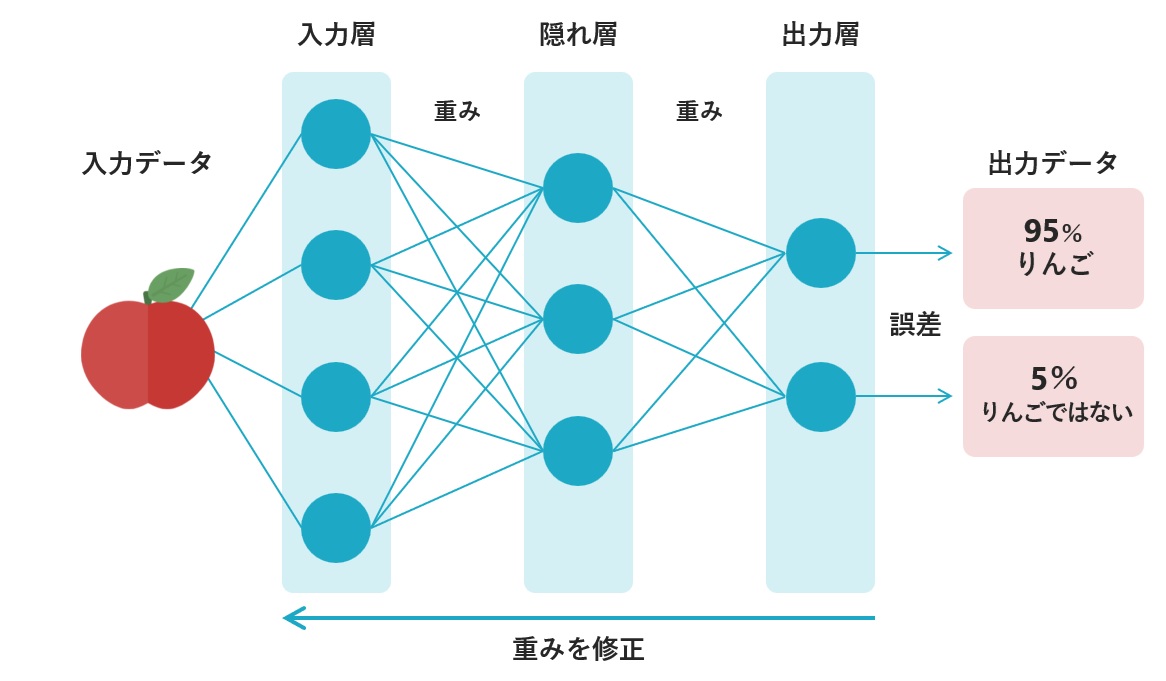
| 1.入力層 | 画像データを受け取る。 |
| 2.隠れ層 | 「赤い」「丸い」「つやがある」などの特徴を分析する。 |
| 3.出力層 | 「これはりんごだ!」と判断する。 |
どう学習するのか?
ニューラルネットワークの学習は、まるで子どもが新しいことを覚えていくような過程です。
準備段階
大量の訓練データを用意します。
| 例 | 大量の「りんご」の写真と、それが「りんご」であるという正解データを用意する。 |
学習段階
AIが分析して判断します。
| 例 |
|
改善段階
判断と調整を繰り返して精度を向上させます。
| 例 |
|
人間の子どもがさまざまな「りんご」を見て学習するように、AIもデータが多いほど、より正確な判断ができるようになります。
このような学習プロセスを経て、画像認識や音声認識など、さまざまなタスクで人間に近い、時には人間以上の精度を実現するのです。
ディープラーニングが得意なこと
ディープラーニングは、特に視覚(画像認識)や聴覚(音声認識)などの非構造データの処理に強みを持っています。
パターン認識
- 医療画像診断:がんの早期発見、骨折の検出、網膜症の診断
- 顔認識:スマートフォンのロック解除、防犯カメラの人物特定
- 音声認識:音声アシスタント、議事録作成、音声翻訳
データ分類・予測
- 不正検知:クレジットカード詐欺の検出、セキュリティ違反の特定
- 需要予測:小売店の在庫管理、電力需要の予測
- 異常検知:製造ラインの不良品検出、設備の故障予知
- 気象予報:降水確率、気温変化の予測
画像処理・生成
- 画質向上:古い写真の修復、解像度の向上
- ノイズ除去:医療画像のクリアな画像生成
- 3D変換:2D画像からの3Dモデル生成
特に大量の教師データがある分野で高い認識精度を実現し、パターンの検出や分類が必要な課題に効果的です。
ディープラーニング技術を基盤として応用し、
自然言語処理に特化させたモデルがLLM(大規模言語モデル)です。
LLM(大規模言語モデル)とは…ディープラーニングを基盤とした自然言語特化モデル
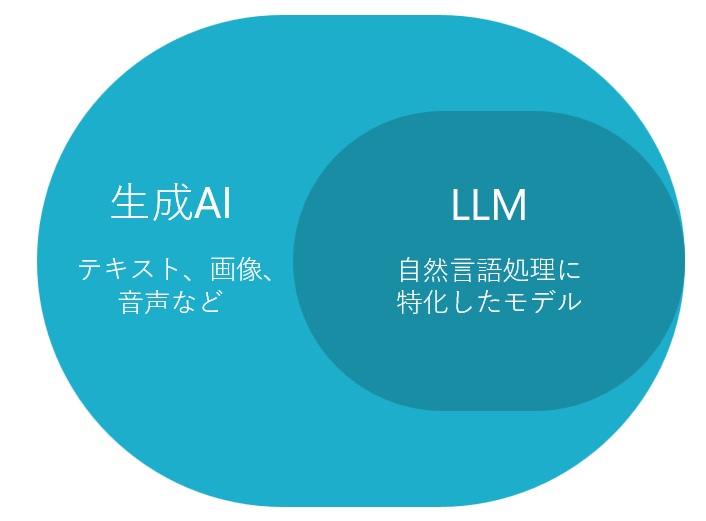
LLMはディープラーニングを基盤とした特定の応用モデルであり、主に自然言語処理(NLP)に特化しています。
大量のテキストデータを用いて訓練され、言語の理解や生成を行う能力を持っています。具体的には、文章の生成、質問応答、翻訳などのタスクを実行するために設計されています。
LLMもディープラーニングを基盤として動いていますが、仕組みが一般的なディープラーニングモデル(例えば画像認識のCNN)とは異なる部分があります。
LLM(大規模言語モデル)をわかりやすく解説!
LLMを一言で表すと、世界中の本や会話から言葉の使い方そのものを学んだ、とてもかしこいAIです。
単に言葉を置き換えるだけの辞書や翻訳ソフトとは違って、LLMは人間のように文章の意味を理解し、状況に合わせて適切な言葉を選んで会話ができます。
LLMの動き方・出力プロセス
私たちは普段、文章を読むとき、言葉の意味や文脈を自然に理解しています。LLMも同様に、文章を理解し、適切な応答を生成します。
LLMでは、Transformerという基本構造が使われています。具体的には、以下のような動きが行われています。
1.トークン化:単語をバラバラにする
まず、文章内の単語や文字を、機械が理解できる最小単位に分割します。
| 例 | 「今日の天気は晴れです」→「今日」「の」「天気」「は」「晴れ」「です」 |
2.埋め込みベクトル化:単語を数値に変える
機械は言葉をそのまま理解できません。そこで、各単語を数値のリスト(ベクトル)に変換 します。
このとき、意味が近い単語ほど似た数値の並びになります。
| 例 | 「晴れ」「快晴」「日和」は似たベクトル、「雨」「曇り」は、別のベクトルに変換されます。 |
3.注意機構(Attention機能):どの単語が大事か考える
LLMは、文の中でどの単語がどの単語と関係が強いかを判断します。
私たちが会話をするとき、「大事な単語」に注目して話の意味を理解するのと同じです。
| 例 | 「今日の天気は晴れです」という文で、「天気」という単語に注目したとき、「晴れ」が関係が強いと判断。 |
4.並列処理と予測:次に何を言うか予測する
文章の複数箇所を同時に分析しながら、文脈から次に続く可能性が高い単語を予測します。
これは、人が会話するときの 「次に何を言えばいいか?」 を考えるのと同じです。

上記の流れを何度も繰り返しながら、私たちが質問すると 「一番自然な答え」を計算して返している のです。
さらに進化したLLM:推論モデル
さらに進化したLLMの代表例が、ChatGPT o1(OpenAI o1)のような推論モデルです。
このモデルは、従来のLLMが持つ「次に何が来るかを予測する力」に加えて、「どうやって問題を解くかを考える力」を持っています。複雑な論理的な質問に対して、問題を段階的に分けて考え、順番に解いていくことができます。
進化したLLMは単なる情報提供を超えて、利用者の意思決定を効率化し、複雑な課題に対する解決プロセスを簡素化します。AIは人間の意思決定や問題解決を支援する存在へと発展しています。
| 予測モデル(従来のLLM) | 推論モデル | |
| 代表的なモデル | GPTシリーズ(GPT-3、 GPT-4、 GPT-4o)など | ChatGPT o1など |
| 得意なこと | 次に来る単語やデータを予測する | 答えを出すための考え方を整理して教える |
どう学習するのか?
LLMは、私たちが基礎教育を受けた後に専門知識を習得するように、段階を経て成長します。
学習フェーズ:基礎知識の習得
まず、広範な知識を学びます。インターネット上の膨大なテキストデータから言語の基本的な理解と知識を獲得します。
| 例 |
|
微調整(ファインチューニング):専門性の向上
基礎学習を終えた後は、より専門的なスキルを身につける段階に入ります。
| 例 |
|
推論フェーズ :出力精度向上
| 例 |
|
LLMが得意なこと
LLMは、人間の言語を理解し、活用する能力に優れています。大量のテキストデータから学習した知識を基に、さまざまな言語タスクを実行できます。
文章の理解と生成
- テキスト要約:長文を的確に短くまとめる
- 文章生成:ブログ記事やレポートの作成
- 翻訳:多言語間の自然な翻訳
対話と質問応答
- チャットボット:ユーザーとの自然な対話
- 質問応答:データベースからの情報検索と回答
- カスタマーサポート:問い合わせ対応の自動化
分析と支援
- テキスト分析:感情分析、トピック分類
- プログラミング支援:コード生成、デバッグ
- 教育支援:個別学習サポート、問題解説
特に自然言語の理解と生成を必要とするタスクで高い性能を発揮し、人間のような柔軟な対話や文章作成が可能です。
一般的なディープラーニングとLLMそれぞれが得意とするケース
上記のように、一般的なディープラーニングモデルとLLMは異なる特性を持ち、それぞれに適した用途があります。
目的や要件に応じて、適切な技術を選択することで、より効果的なAI活用が可能になります。
一般的なディープラーニングモデルを活用すべきケース
特定のタスクに特化し、高速で正確な判断が求められる場面で真価を発揮します。
向いているシーン
- リアルタイムでの判断が要求される場面
- 正確なパターン検出が必要な場合
- 遅延が許されない状況での高速な判断
- 明確な基準での判断が求められる場合
具体例
- 製造ラインでの品質検査
膨大な画像データから不良品を高精度で検出でき、人間よりも一貫性のある判断が可能です。 - 医療現場でのX線やMRI画像の分析
微細な異常を検出する高いパターン認識能力があり、診断の補助に役立ちます。 - 自動運転における道路標識の認識や障害物の検出
リアルタイムで複雑な環境の認識・判断が可能で、安全性を向上できます。 - 金融分野での不正取引の即時検知
大量のトランザクションデータから不正パターンを高速かつ精度高く検出可能です。 - セキュリティシステムでの顔認証
複雑な顔の特徴を認識し、高い精度で個人を識別できます。
一方、より柔軟な思考と対話が必要な場面では、LLMが力を発揮します。
LLMを活用すべきケース
人間との自然なコミュニケーションや複雑な文脈理解が必要な場面に最適です。
向いているシーン
- 柔軟な対話が求められる場合
- 文脈理解が必要な場合
- 創造的なコンテンツ生成が求められる場合
具体例
- カスタマーサポート
自然言語での質問を理解し、迅速かつ正確に回答を提供できるため、効率が向上します。 - 大量の文書データの分析や要約
大量の情報を短時間で処理し、要点を抽出する能力に優れているため、時間を大幅に節約できます。 - プログラミング支援
コードの自動生成やデバッグのヒントを提供することで、開発者の生産性を向上させます。 - 創造的な文章作成が必要なコンテンツ制作
豊富な言語データからインスピレーションを引き出し、アイデアを形にするのが得意です。 - 教育支援
質問への回答や学習資料の生成を通じて、個別の学習ニーズに対応できます。
両方を組み合わせる場合
さらに、両者の長所を組み合わせることで、より包括的かつ高度なソリューションを実現できます。
向いているシーン
- 画像・音声認識と言語処理の連携が必要な場合
- 分析結果の言語化が求められる場面
- ユーザーとの対話を伴う高度な判断が必要なケース
- リアルタイム処理と詳細な説明の両方が求められる状況
事例
- 自動運転:道路状況解析+ナビゲーション
ディープラーニングは道路状況や障害物を高精度で解析し、LLMは音声やテキストで運転者に的確なナビゲーション指示を提供できます。 - 医療分野: 画像診断+レポート生成
ディープラーニングがX線やMRI画像の異常を検出し、LLMが診断結果をわかりやすく説明したレポートを自動生成します。 - 製造現場:不良品検知+分析レポート生成
ディープラーニングで不良品を正確に検出し、LLMがその原因や改善提案を含む詳細な分析レポートを作成します。
技術トレンドと未来の展望
ディープラーニングと大規模言語モデル(LLM)の組み合わせは、今後さらに多様な分野での応用が期待されています。
ディープラーニングは…
さまざまな環境下でも安定した認識精度を実現する環境適応と、少量のデータでも効果的に学習できる効率的な学習能力の向上が進んでいます。特に、小型デバイスでの高速処理を可能にするエッジAIの発展により、より身近な場面での活用が広がっています。
LLMは…
画像や音声などのマルチモーダル対応を強化し、より総合的な情報処理が可能になってきています。また、特定分野での専門性が深まり、判断根拠を明確に示せる説明可能性も向上しています。
さらに、LLMの進化に伴い、AIエージェントとしての役割が強化され、複雑なタスクの自動化や高度な意思決定支援が実現し、業務効率化や新たな価値創出が促進されると考えられます。
まとめ:利用者側も各AIの得意分野を見極めて活用すべき!
ディープラーニングは人間の脳の仕組みを模倣した技術であり、LLMはその技術を基盤に自然言語処理に特化させたモデルです。
LLMはディープラーニングを基盤としているものの一般的なディープラーニングとは異なる得意分野を持っています。
一般的なディープラーニングは高速・正確なパターン認識に、LLMは柔軟な対話や文章生成に強みを発揮します。
得意分野をおさらい
- 一般的なディープラーニング:リアルタイムの判断と正確なパターン検出が得意
- LLM:柔軟な対話と創造的なコンテンツ生成が得意
- 組み合わせ:パターン検出と言語処理の連携が必要な場合などに最適













