
検索エンジンの仕組み

現在の検索エンジンは、ほとんどがロボット型検索エンジンです。ロボット型検索エンジンは以下の3つのステップを踏むことで、検索順位を決定しています。
- ステップ1:インターネット上に存在するWEBページの情報収集(クロール)
- ステップ2:収集した情報を解析し、データベースに登録(インデックス)
- ステップ3:データベースに登録されたものを、アルゴリズムに基づいて順位を決定し、検索結果へ表示(ランキング)
今回の記事のテーマである「クローラー」は、この中のステップ1に大きく関係しています。
クローラーとは何か
クローラーは、英語の「crawl(這う)」を語源としており、インターネット上を巡回することでWEBサイトや画像、動画などのあらゆるデータを取得するプログラムのことです。
ロボットやボットと呼ばれたり、サイト内に貼られたリンクをめぐることからスパイダーと呼ばれたりすることもあります。
クローラーの役割
ロボット型検索エンジンが検索順位を決定するまでの3つのステップを見るとわかるように、WEBサイトが検索結果に表示されるためには、まずクローラーにサイトを巡回してもらわないと始まらないわけです。
クローラーにページ情報を読み込んでもらうことで、初めて検索エンジン側はWEBページの存在を知ることができます。
主なクローラーの種類
主な検索エンジンのクローラーには以下のものがあります
- Googlebot(Google)
- Bingbot(マイクロソフトが運営しているBing)
- Yahoo Slurp(日本以外のYahoo!)
- Baiduspider(百度)
いろいろクローラーはありますが、日本の検索エンジンのシェアは9割がGoogleなので、SEO対策をする際はGooglebotを重視しましょう。
クローラーが取得するファイルの種類
クローラーは「HTTP/HTTPSプロトコル」を使ってサーバーと通信を行うので、「HTTP/HTTPS」で取得できるものに関してはすべて取得可能です。
具体的には以下のようなファイルです。
- HTML
- CSS
- JavaScript
- 画像(GIF/JPEG/PNG/WebP/SVG)
- 動画(MP4/WebMなど)
- オフィス文書(Word/Excel/PowerPoint)
クローラーが巡回したページの確認方法

検索エンジンの仕組みの部分で説明したように、WEBサイトやページを検索結果に表示させるためには、クロールそしてインデックされる必要があります。そのため、新たにサイトやページを作成した場合は、クローラーが巡回し、正常にインデックスされているかどうかを必ず確認するようにしましょう。
ここでは2つの確認方法をご紹介しておきます。
確認1:Googleサーチコンソール
Googleサーチコンソールは、Googleが提供しているインターネット検索の分析ツールで、キーワードの表示回数や順位の推移などを確認することができます。
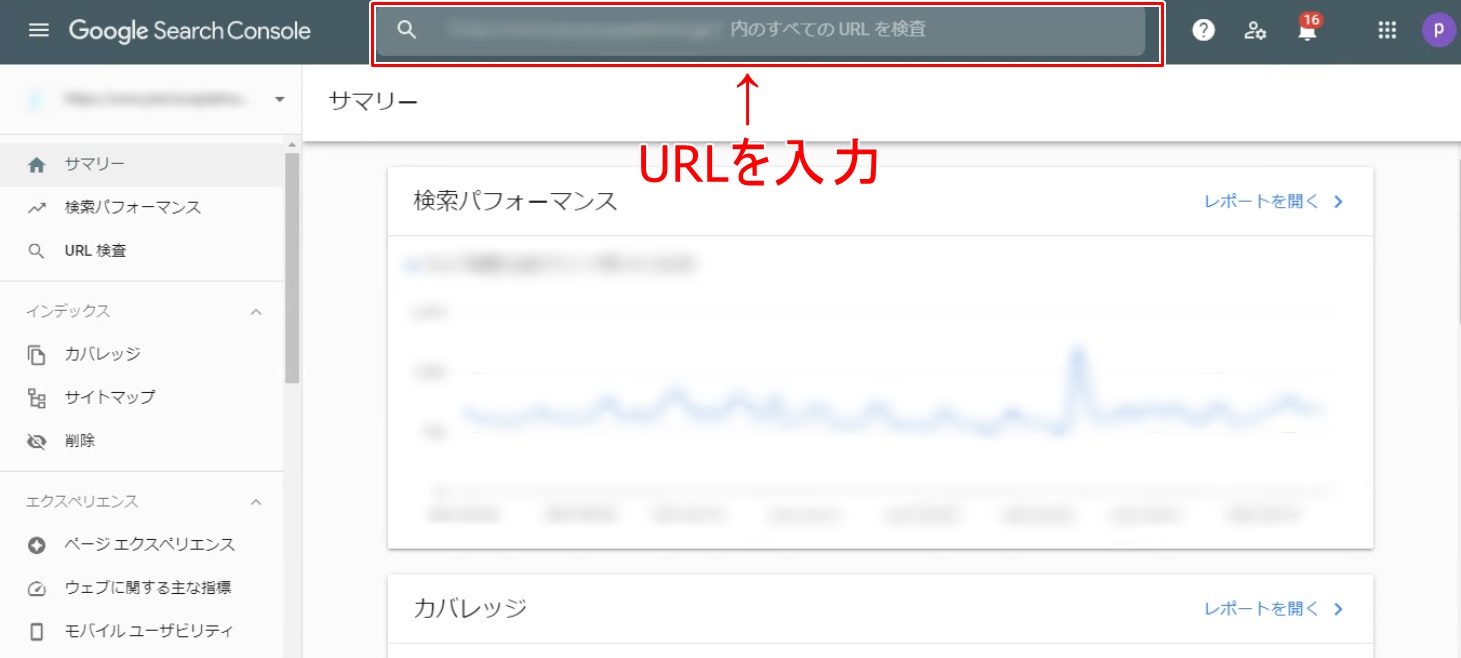
このツールを使用しての確認方法は、まずGoogleサーチコンソールにログインした後、サイト上部にある検索窓に確認したいURLを入力します。
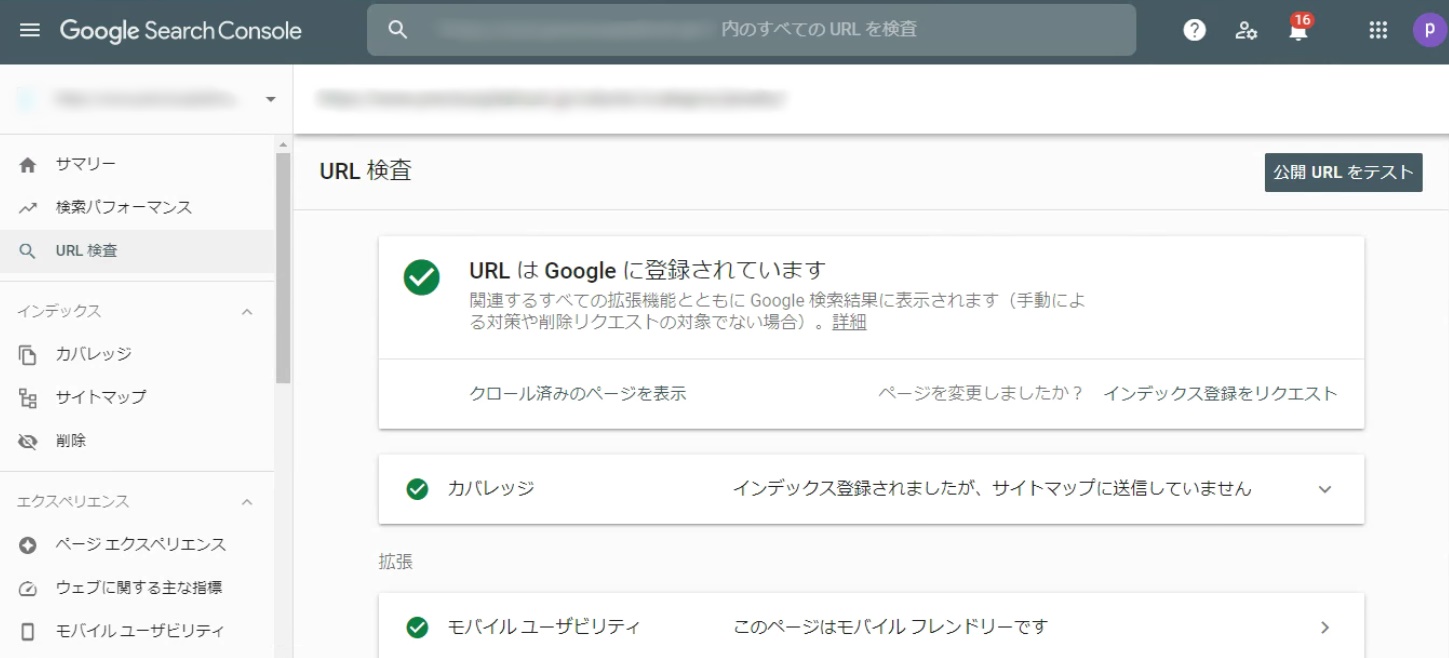
クローラーが巡回を終え、インデックスされていると、画像のように「URLはGoogleに登録されています」と表示されます。
確認2:「site:」検索
Googleの検索窓に「site:確認したいサイトのURL」を入力して検索します。クロールされて正常にインデックスされていれば、検索結果に確認したいサイトが表示されます。
site:検索はあくまでもインデックスされているかの簡易的な確認方法ではありますが、ツールを使わず手軽に調べられる方法として覚えておいても良いでしょう。
クローリングされたくない場合はどうする?
テスト運用中のページやまだ準備段階でコンテンツがそろっていないサイトもクローリングされてしまうことがあります。そのため、まだクローリングされたくない場合には、robots.txt(ロボットテキスト)をトップディレクトリにアップロードすることで、クローラーを制御することが可能です。

クローラビリティを向上させるには?

クローラビリティとは、クローラーのページの見つけやすさや認識のしやすさのことです。
クローラーが見つけやすく、わかりやすいサイト・ページにすることでクローラビリティが向上するわけですが、具体的にどのような方法をとれば良いのでしょう?
サイトのURLを見直す
内容がまったく同じなのに「www.」があるURLとないURLが存在したり、URLの末尾に「/index.html」がついているものとついていないものが存在したりすると、重複コンテンツとみなされ、Googleからマイナス評価を受けてしまいます。
サイトのURLを見直して、重複ページを発見した場合には、301リダイレクトをかけてURLの正規化を行いましょう。
被リンクを増やす
自然な被リンクはGoogleからの評価をあげるだけでなく、クローラーがサイトを見つけやすくなります。
3クリックで到達できる構造にする
クローラーは、階層の浅いページから優先的にクロールを実行するので、トップページから2クリックですべてのページにいけるような構造にしましょう。
階層が浅いと、それだけクローラーが隅々まで巡回しやすくなります。
リンクのないページをなくす
クローラーはリンクをたどってページをクロールし、インデックスするわけですから、リンクがないサイト、ページは発見されにくくなってしまいます。
基本的にリンクのないページというのはなくし、できる限り内部リンクを貼るようにしましょう。そもそも関連する本文や見出しがないという場合は、内部リンクを貼るためのコンテンツを作成することをおすすめします。
パンくずリストを設定する
パンくずリストというのは、ユーザーが今現在、WEBサイト内のどこにいるのかを表示したリスト(画像の青い四角の部分)のことです。

一般的に、ページの上部もしくは下部に設置されています。
パンくずリストがあると、ユーザーだけでなくクローラーもサイト内での現在地がわかりやすくなり、クローラーの回遊率を上げることにつながるのです。
巡回申請をする
Googleの場合、Googleサーチコンソールを使うと、クロールの申請をすることができます。
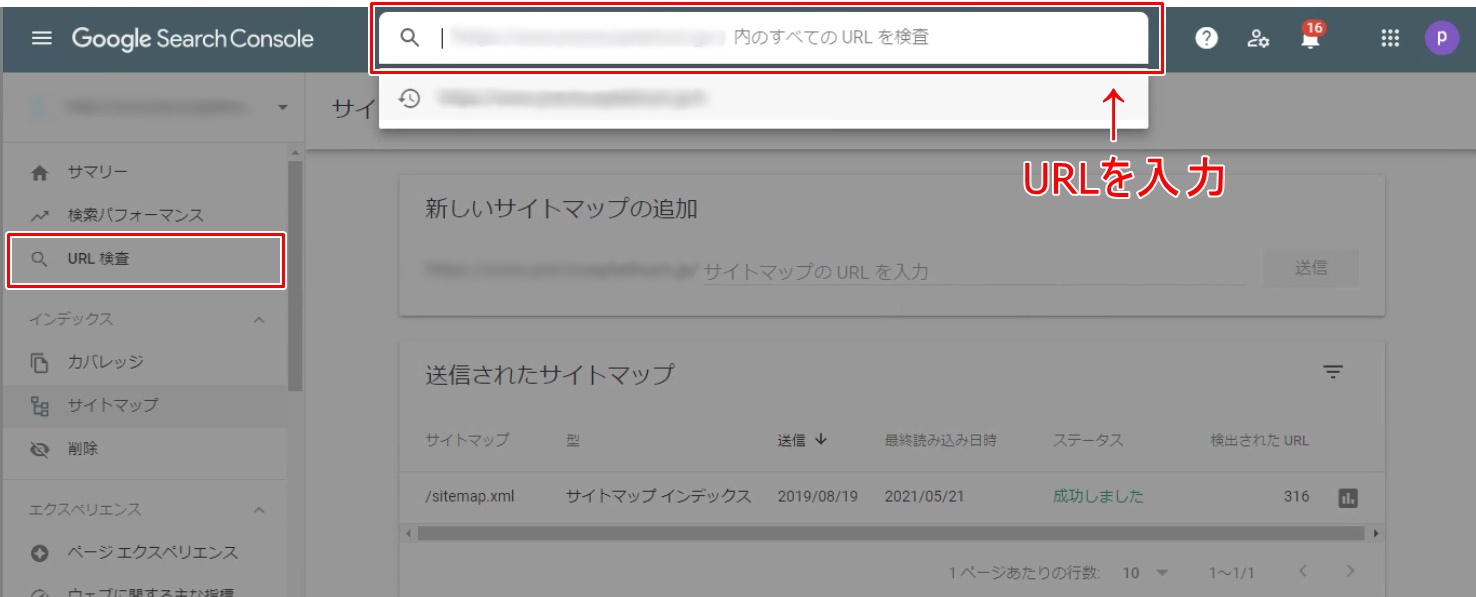
方法としては、まずGoogleサーチコンソールにログインし、URL検査をクリックします。次に、検索窓に申請したいサイトのURLを入力します。
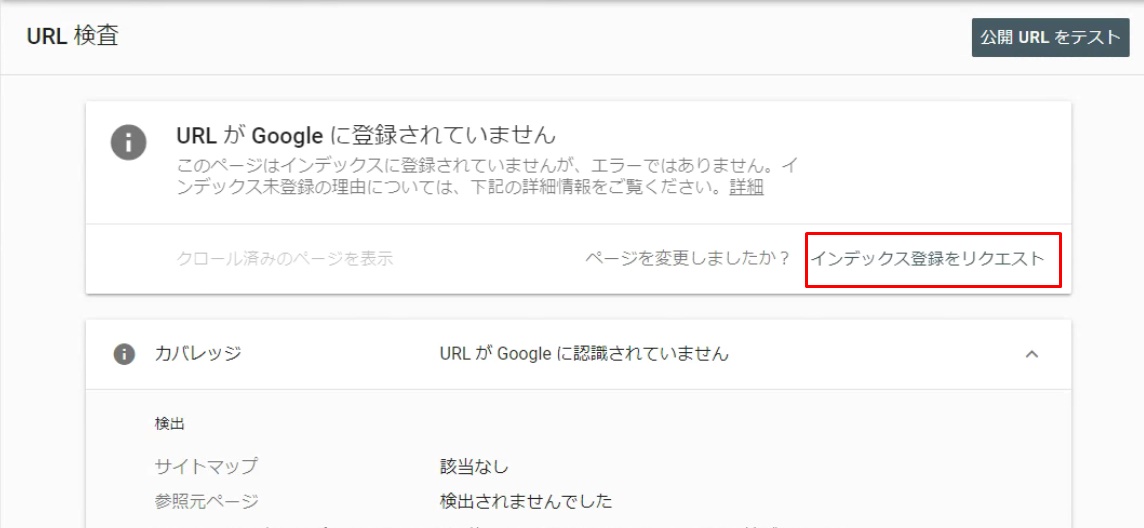
サイトが未登録の場合、上の画像のように「URLがGoogleに登録されていません」というメッセージとともに「インデックス登録をリクエスト」というものが表示されるのでクリックします。「インデックス登録をリクエスト済み」と出れば、申請自体は完了です。
なお、新しく投稿したページをインデックスするために「Fetch as Google」を利用していた方もいるかもしれませんが、旧サーチコンソールでは2019年3月28日をもってFetch as Googleの使用ができなくなりましたので、今後インデックス状況の確認やインデックス登録のリクエストを行う場合は、上記の方法で行うようにしましょう。
画像リンクではなくテキストリンクを設定する
クローラーはテキストを優先的に巡回してくるので、画像リンクよりもテキストリンクを設定したほうが、クローラビリティの向上につながります。
アンカーテキストの内容を改善する
アンカーテキストというのは、リンクが貼られている部分のテキストを指します。
クローラーは、アンカーテキストによってリンク先の内容がどういったものなのかを把握するので、「詳しくはこちら」など雑なテキストにしてしまうと概要が把握できなくなってしまいます。さらに、サイトの階層構造もわかりにくいので、回遊率が下がってしまいます。
サイトマップを送信する
サイトマップは、サイト全体のページ構成を一覧で記載したものです。このサイトマップをGoogleサーチコンソールで送信すると、Googleにページの存在を伝えることができるので、クローリングしてもらうことができます。
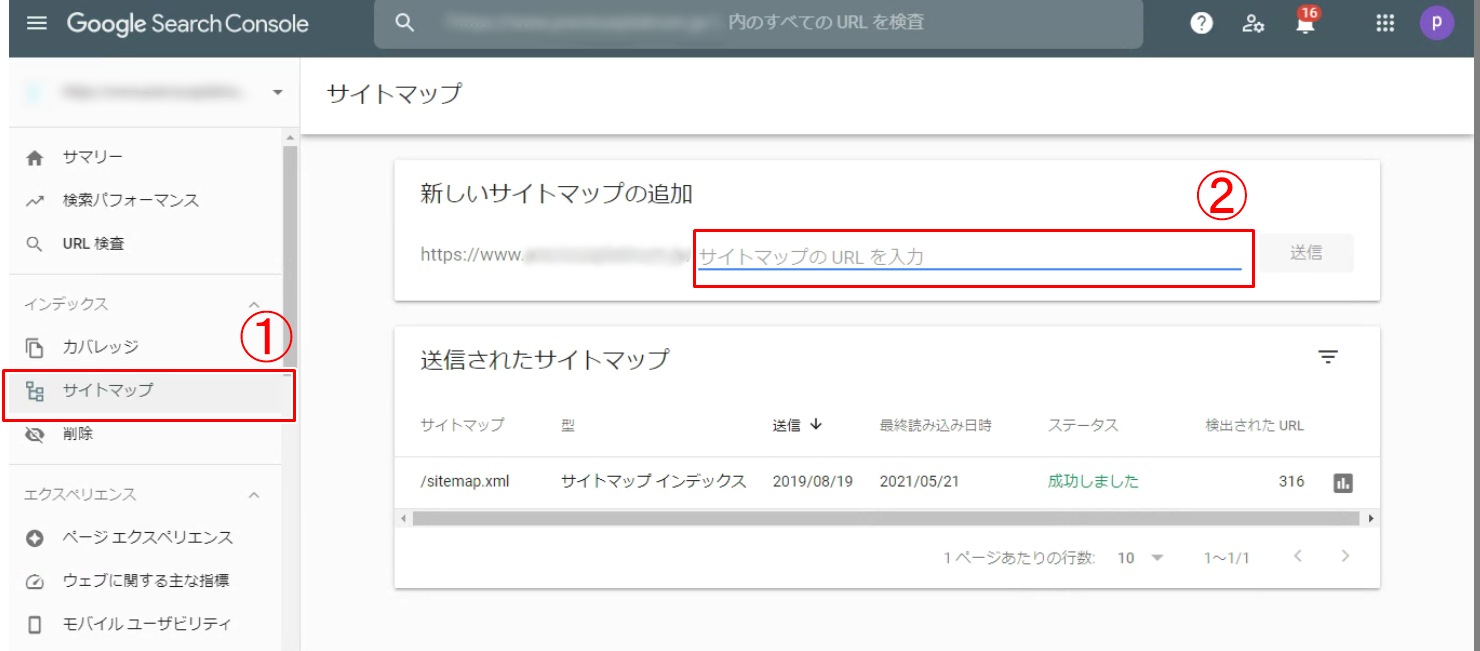
具体的な手順としては、Googleサーチコンソールにログイン後、メニューの中のサイトマップを選択します。次にsitemap.xml(サイト全体のページ構成を一覧で記載したxml形式のファイル)が保存してあるURLを入力します。最後に横にある送信ボタンを押せば送信することができます。
まとめ

自社サイトの検索順位を上げるために、さまざまなSEO対策を講じている方も多いと思いますが、そもそもクローラーが巡回してくれなければ、検索結果に表示されません。コンテンツ制作に力を入れるのももちろん重要ですが、それと同時にサイト内部を整え、クローラビリティを向上させることも重要視するようにしましょう。














